|
| Для зарегистрированных пользователей |
|
Навигация по иерархиям и сетям в реляционных базах данных
Зачем бывают нужны иерархии
В последнее время часто встречаются программные системы, использующие иерархии на уровне реляционной БД. Обычно иерархии нужны для двух целей: каталогизация либо разграничение прав доступа. Для задач разграничения прав доступа характерен подход, когда какое-либо право доступа должно автоматически распространяться на некоторые новые объекты. Такое требование удобно выполнять с помощью т.н. "рекурсивных" прав доступа, распространяющихся вниз по иерархии объектов. При этом автоматизм распространения прав доступа достигается за счет того, что новые объекты добавляются в специально отведенную ветку иерархии.
Проблематика работы с иерархиями в реляционных БД
Не будем подробно останавливаться на том, каким образом обычно реализуют иерархии в реляционных БД. Итак, пусть есть иерархия, построенная на отношении с атрибутами id, parent_id. Рассмотрим типичные задачи, связанные с некоторым элементом такой иерархии:
- Выборка непосредственного родительского элемента.
- Выборка непосредственных дочерних элементов.
- Выборка всех прямых родительских элементов.
- Выборка всех прямых дочерних элементов.
- Выборка некоторых прямых родительских элементов, по относительному уровню в иерархии (например, со второго по четвертый уровень, что означает выбор родителя^2, родителя^3, родителя^4).
- Выборка некоторых прямых дочерних элементов, по относительному уровню в иерархии.
Первые две задачи достаточно хорошо оптимизируются с помощью индексов по полям id и parent_id. Для решения остальных обычно используется программный код, производящий рекурсивный обход иерархии. Некоторые СУБД даже предоставляют языковые расширения SQL, позволяющие делать подобные рекурсивные обходы (например, в Oracle это start with… connect by…).
Рекурсивный обход для решения указанных задач зачастую является не самым лучшим решением. Причины:
- Во многих СУБД нет языковой поддержки, приходится разрабатывать программный код рекурсивного обхода вручную.
- В некоторых из упомянутых задач рекурсивный обход будет выбирать лишние элементы, которые нужно будет отфильтровывать. Например, для выбора слоя на относительном уровне 10 придется также выбирать элементы с первого уровня по девятый. Это снижает эффективность выборки.
- Рекурсивный обход (реализуемый как языковыми расширениями СУБД, так и вручную) производит поиск по индексу для каждого выбираемого элемента (а не только для первого или последнего). Временная сложность такого поиска - как правило, ln n. Соответственно, временная сложность выборки достаточно большого количества элементов иерархии - n ln n. Это не слишком хороший показатель. Было бы куда лучше выбирать n элементов за время O(n).
Способы оптимизации для навигации по иерархии
Если иерархия статична (элементы редко добавляются и удаляются), самая простая оптимизация - содержать последовательность рекурсивного обхода иерархии в заранее просчитанном виде. В самом деле, если сопоставить с каждым элементом иерархии номер этого элемента по порядку рекурсивного обхода, то обход можно будет делать движением по индексу. Тем самым время выборки n элементов составит O(n), что существенно лучше, чем O(n ln n).
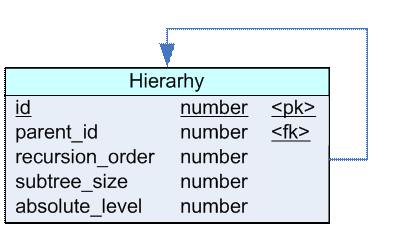
Рисунок 1
На рисунке 1 показана таблица, реализующая такой способ оптимизации. Каждая запись в таблице - элемент иерархии с идентификатором id и указателем на родительский элемент parent_id. Кроме этих атрибутов, есть еще порядковый номер рекурсивного обхода recursion_order, количество элементов поддерева subtree_size и уровень элемента в иерархии absolute_level. Ниже приведены характерные запросы, которые можно производить с помощью этой оптимизации.
 Пример 1. Выборка поддерева элемента node (включая сам элемент): Пример 1. Выборка поддерева элемента node (включая сам элемент):
select * from Hierarchy
where recursion_order
between node.recursion_order
and (node.recursion_order + node.subtree_size - 1)
|
 Пример 2. Выборка слоя (на уровнях 3-5) в поддереве текущего элемента node: Пример 2. Выборка слоя (на уровнях 3-5) в поддереве текущего элемента node:
select * from Hierarchy
where recursion_order
between node.recursion_order
and (node.recursion_order + node.subtree_size - 1)
and absolute_level - node.absolute_level between 3 and 5
|
В обоих запросах целесообразно использовать уникальный индекс по полю recursion_order. Причем во втором примере для выборки нужного слоя придется произвести выборку всего поддерева, с последующей фильтрацией записей по полю absolute_level.
К сожалению, в случае динамично изменяющейся иерархии такой способ не подходит, поскольку относительно небольшие изменения (например, добавление одного элемента) требуют пересчета O(n) порядковых номеров. Кроме этого, указанный подход устраняет лишь некоторые из описанных выше недостатков "классического" рекурсивного обхода.
Теперь рассмотрим случай, когда иерархия не статична. Предлагаемый способ навигации по изменчивым иерархиям требует построения транзитивного замыкания отношения родитель-потомок. Практически это реализуется следующим образом. Добавляется новое отношение с атрибутами upper_id, lower_id, relative_depth, которое содержит все прямые генеалогические отношения (в т.ч. родитель - потомок, родитель родителя - потомок, родитель родителя родителя - потомок, и т.д.). Если в соответствующей таблице сделать нужные индексы, появляется возможность быстрой выборки как любых родителей, так и любых потомков (в т.ч. послойно).
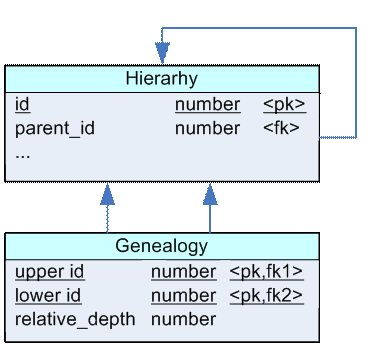
Рисунок 2.
На рисунке 2 показана таблица Hierarhy, а также связанная с ней таблица Genealogy. В таблице Genealogy каждая запись - это прямая генеалогическая связь между двумя элементами иерархии. Идентификатор верхнего элемента представлен атрибутом upper_id, нижнего элемента - lower_id, уровень одного элемента относительно другого - атрибутом relative_depth.
Замечательная особенность этого способа навигации - при его использовании подавляющее большинство задач по выборке данных из иерархии более не требуют разработки процедурного программного кода. Вместо этого, появляется возможность выборки с использованием только декларативных SQL-запросов.
 Пример 3. Выборка всех прямых родительских узлов (по всем уровням иерархии выше текущего элемента): Пример 3. Выборка всех прямых родительских узлов (по всем уровням иерархии выше текущего элемента):
select upper_id from Genealogy
where lower_id = <текущий элемент>
|
 Пример 4. Выборка прямого родительского узла на втором уровне (родитель родителя): Пример 4. Выборка прямого родительского узла на втором уровне (родитель родителя):
select upper_id from Genealogy
where lower_id = <текущий элемент>
and relative_depth = 2
|
 Пример 5. Выборка всех дочерних узлов (поддерева текущего элемента): Пример 5. Выборка всех дочерних узлов (поддерева текущего элемента):
select lower_id from Genealogy
where upper_id = <текущий элемент>
|
 Пример 6. Выборка слоя (на уровнях 3-5) в поддереве текущего элемента: Пример 6. Выборка слоя (на уровнях 3-5) в поддереве текущего элемента:
select lower_id from Genealogy
where upper_id = <текущий элемент>
and relative_depth between 3 and 5
|
Рассмотрим типичные емкостные и временные сложности, связанные с этим подходом (без учета особенностей реализации СУБД):
| Характеристика |
Типичное значение |
Предельное значение |
| Емкостная сложность |
n ln n |
n2 |
| Время выборки любого прямого предка |
O(1) |
O(1) |
| Время выборки слоя прямых потомков, в расчете на одного потомка |
O(1) |
O(1) |
| Время добавления/удаления элемента из иерархии |
O(ln n) |
O(n) |
Исходя из приведенных характеристик, в каждой конкретной ситуации можно делать выводы о целесообразности применения этой оптимизации. Типичные значения характеристик соответствуют сбалансированной иерархии. Предельные значения соответствуют вырожденной иерархии, состоящей из единственной длинной ветки.
Зачем бывают нужны сети
Пример необходимости сети покажем на задаче разграничения прав доступа. Использование иерархии для разграничения прав доступа не всегда приводит к простым решениям. Как будет показано ниже, для эффективного использования "рекурсивных" прав иногда требуется более гибкая навигационная структура, а именно - сеть. Пример реализации подобной сети в реляционной базе данных показан на рисунке 3.

Рисунок 3.
Предположим, что пользователи отправляют друг другу документы, причем каждый пользователь имеет право видеть только документы, отправленные им, и документы, отправленные ему. Если эту задачу решать путем разграничения прав доступа на иерархии, то потребуется n2 каталогов, в которые будут раскладываться эти документы (каждый каталог будет соответствовать переписке конкретного отправителя с конкретным адресатом). Такое решение неудобно и малоэффективно, поскольку его емкостная сложность - n2.
Вариантом решения является структурирование объектов в сеть, с распространением "рекурсивных" прав доступа вдоль ребер этой сети. Принципиальное отличие от иерархии - в возможности "положить" объект не в один каталог, а сразу в несколько. Задав различные рекурсивные права доступа к этим каталогам, можно добиться, чтобы документ был виден разным категориям пользователей. В приведенной выше ситуации для каждого отправителя и получателя будет заведен свой каталог, на содержимое которых им будут выданы права (итого 2n каталогов). Посылаемый документ будет "положен" сразу в два каталога: каталог отправителя и каталог получателя. Таким образом, отправитель и получатель получат необходимые права доступа к этому документу, а все остальные пользователи - нет.
Цель приведенного выше примера - показать целесообразность использования сети в задачах разграничения прав доступа. Очевидно, что подобных задач, требующих реализации сетей, очень много. Ниже рассмотрен подход к оптимизации подобных задач.
Оптимизация навигации по сети
Навигация по сети напоминает навигацию по иерархии. Что характерно, и оптимизация производится аналогичным способом: созданием транзитивного замыкания отношения "предыдущий узел"-"следующий узел". Иначе говоря, следует создать новое отношение, которое будет содержать всевозможные пары таких узлов (node_from, node_to), что из node_from можно попасть в node_to.
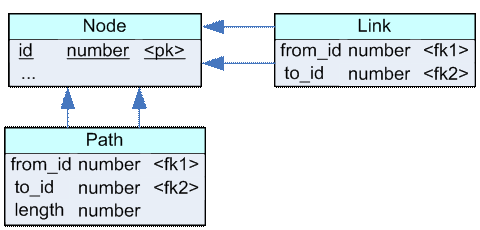
Рисунок 4.
На рисунке 4 показан вариант такой оптимизации. Вдобавок к таблице Node, содержащей атрибуты узла, и таблице Link, содержащей ребра сети, вводится таблица Path, которая содержит пути из узла в узел. В таблице Path атрибут from_id указывает на исходный узел сети, атрибут to_id - конечный узел сети, а атрибут length - на длину пути.
В зависимости от разновидности сети и постановки задачи, таблица Path может содержать как всевозможные пути из узла в узел, так и некоторые избранные пути, например, минимальный путь. Например, для конечной ациклической сети можно гарантировать конечное количество путей из узла в узел, поэтому допустима такая постановка, при которой в таблицы Path будут храниться всевозможные пути. Покажем характерные навигационные запросы, которые можно производить с помощью этой оптимизации.
 Пример 7. Выборка множества узлов, в которые можно попасть из данного узла: Пример 7. Выборка множества узлов, в которые можно попасть из данного узла:
select distinct to from Path
where from_id = <текущий элемент>
|
 Пример 8. Выборка множества узлов на определенном расстоянии от данного узла: Пример 8. Выборка множества узлов на определенном расстоянии от данного узла:
select distinct to from Path
where from_id = <текущий элемент>
and length = <расстояние>
|
Следует заметить, что для максимальной эффективности запроса в примере 7 нужно, чтобы в таблице Path был уникальный индекс по полям from_id, to_id. В этом случае индекс сможет использоваться для выборки записей напрямую, без последующей сортировки значений. Иначе говоря, этот запрос наиболее эффективен в такой постановке задачи, когда таблица Path хранит не более одного пути для каждой пары узлов (например, самый короткий путь). Характерно, что такая постановка допускает цикличность сети.
Что касается запроса в примере 8, он выбирает все узлы на определенном расстоянии от данного, и поэтому таблица Path должна содержать все возможные пути различной длины. Естественно, этот способ оптимизации возможен только для ациклических сетей. Для того, чтобы этот запрос выполнялся наиболее эффективно, можно использовать уникальный индекс по полям from_id, length, to_id.
Как видно из приведенных выше примеров, способ оптимизации может иметь ряд модификаций. У этих модификаций есть как общая часть (хранение просчитанных путей), так и различающаяся часть (какие именно пути хранить, под какие характерные запросы индексировать таблицы). Конкретную модификацию можно рекомендовать только под конкретную постановку задачи.
Заключение
В статье были рассмотрены способы, позволяющие существенно упростить выборку элементов из иерархий и сетей, построенных в реляционных базах данных. Описанные подходы несут в себе сразу два преимущества:
- Достигается снижение временных сложностей выполнения типовых операций.
- Возрастает удобство и качество разработки, за счет выборки данных путем декларативных запросов.
За рамками статьи остались такие вопросы практической реализации, как способы поддержания вспомогательных таблиц, схемы индексирования, и т.д. Эти вопросы не рассмотрены потому, что детали их решения обычно крайне сильно зависят от постановки задачи. Тем не менее, следует иметь в виду, что описанные в статье подходы были многократно использованы, и уже успели продемонстрировать свою эффективность в реальных проектах.
|
